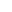

Code:void btf(int size, int pos, char curr[]) { // size = Aktuelle Länge; pos = Aktuelle Position; curr = Das aktuelle Passwort char* charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZ123456789"; // Das Charset halt :D int i; if(pos < size){ // Wenn wir noch nicht beim letzen Buchstaben sind... for(i=0; i<strlen(charset);i++){ // Gehe das ganze Charset durch... char test[strlen(curr) + 2]; //Hänge die Buchstaben hinten an... strcpy(test, curr); int len = strlen(test); test[len] = charset[i]; test[len+1] = '\0'; btf(size, pos+1, test); // Wir sind ja nicht beim letzten Buchstaben, also rufen wir uns selbst auf. Wenn der letzte Buchstabe erreicht ist, dann gehen wir wegen der For oben im Charset eins weiter. Das macht natürliche jede Instanz von BTF, und somit kommst du auf alle Möglichkeiten. }} else { // wir haben ein Passwort generiert! if(match(crackme, curr) == 1) { // Passt der Hash? printf("Your Hash has been Cracked. md5( %s ) == %s\n", curr, crackme); // Ausgabe, wir haben was gecracked! exit(0); } } }
Mir geht es auch absolut nicht um Geschwindigkeit, sondern eher um die Rekursiven Funktionen. Wenn ich was cracken will dann löse ich das über einen GPU-Cracker...In der Hinsicht hin ist sein Source Code wesentlich perdormanter als deiner.
Ergebnis 21 bis 26 von 26
Thema: code optimierung
-
13.06.2010, 12:56 #21Stanley Jobson

- Registriert seit
- 01.02.2010
- Beiträge
- 735

-
13.06.2010, 13:32 #22Bugbear Wurm
- Registriert seit
- 01.01.2007
- Beiträge
- 230
was ist aber wenn ich das ganze angeh wie bei meiner funktion, d.h. alle nachteile ausbügle aber das ganze rekursiv löse? bin ich dann nur flexibler oder auch schneller?
//edit
wow, danke bonkers für die kommentierung, das hilft mir sehr In§@N¡T¥
In§@N¡T¥
-
13.06.2010, 19:26 #23OpCodeKiddy
- Registriert seit
- 30.03.2009
- Beiträge
- 442
1. keine Kopierereien und "höhere" Datentypen wie Strings (ein "string[x]" Zugriff artet nämlich intern in einige Calls aus und ist keineswegs mit dem "char* hallo[x]" gleichzusetzen). Gleiches gilt für "Concatenierungen" oder gar "+" Operatoren bei Strings.
nimm ein chararray, initialisiere es am Anfag mit 0 und schreibe direkt die Zeichen rein.
2. alle Infos möglichst im voraus berechnen - so auch die Passwortlänge.
3. MD5 Routine aus den Libs ist keineswegs optimal - denn diese sind dazu gedacht, "echte" Daten zu hashen. Sofern man aber auf 12-13 Zeichen beschränkt ist, kann man einiges wegoptimieren:
das ist nämlich der Algo:
Message-Digest Algorithm 5 – Wikipedia
z.B dieser Schritt:also das einbeziehen der Eingabe (=w(g) Wert):Code:b := ((a + f + k(i) + w(g)) leftrotate r(i)) + b
so schaut der Speicherzugriff bei 20 Zeichen und 64 Runden:
und so bei 4 Zeichen:
hier kann man sich also jede Menge Speicherzugriffe sparen.
Zudem lassen sich die letzen 15-18 der 64 Runden (länger her) zurückrechnen, was wiederum eine "Verschnellerung" um 25% bietet. Den ultimativen Boost bringt aber Parallelisierung mittels MMX oder gleich SSE:
Software optimization resources. C++ and assembly. Windows, Linux, BSD, Mac OS X
(hier solltest du, je nach Kenntnissstand, ruhig einige Wochen zum durcharbeiten einplanen )
)
Damit erreicht man mehere zig Mio Hashs pro Sekunde (z.B auf meinem 3 Jahre altem Laptop 32 Mio Hashs/s pro Kern - gegenüber BarsWFs 27 Mio H/s ). Setzt aber voraus, dass man sich mit SSE erstmal beschäftigt (C++ Compiler wird hier einem keineswegs die Arbeit abnehmen - vielleicht nur insofern, dass er die SSE Register selbstständig vergibt, allerdings muss man dem Compiler an vielen Schritten zu seinem "Glück" verhelfen. Letzendlich schaut der hochoptimierte Code wie Macro-Asm aus:
Distracted: New and faster EmDebr finally done
(Md5 cracker mit Source, unwesentlich langsamer als BarsWF)
4. Nicht zuletzt solltest du dich mit Profilersoftware vertraut machen, um die tatsächlichen Problemstellen zu finden. Zumindest eine gute Timerbibliothek suchen und einbauen, so dass man die Zeit für einzelne Abschnitte messen kann und so abschätzen, was am meisten Rechenzeit kostet und optimiert werden muss.Geändert von EBFE (13.06.2010 um 19:38 Uhr)
TrueCrypt/RAR/Zip Passwort vergessen und das Bruten dauert ewig? Oder brauchst du fein abgestimmte Wortlisten? Hilf dir selbst mit WLML - Word List Markup Language
Gib Stoned/Mebroot/Sinowal und anderen Bootkits keine Chance: Anti Bootkit v 0.8.5
-
-
13.06.2010, 22:46 #24Bugbear Wurm
- Registriert seit
- 01.01.2007
- Beiträge
- 230
wow, danke für diesen post.. is ja mal hammer.
da werd ich mich mal durcharbeiten, auch wenns viel arbeit wird^^ aber ich hab gemerkt dass plumpes lesen und sich seine gedanken machen nicht sonderlich viel hilft... deswegen stürz ich mich ins coden :x so lernt man am besten^^ den unteren abschnitt werd ich da natürlich erstmal etwas hinten anstellen da sich das sehr komplex anhört, erstmal will ich die basics perfekt drauf haben.
aber nochmal zurück zu den letzten posts... ich hab das jetzt auf rekursiv und char umgestellt (auch wenn nochnicht perfekt, hatte einfach kein kopf mehr) aber im vergleich zu meiner funktion hab ich nen enormen performance verlusst... manche einfache hashs kamen nichtmal zu nem ergebnis weils mir einfach zu lang dauerte wo meine funktion knapp ne minute gebraucht hat. deswegen frag ich mich... hat meine funktion nen fehler oder ist die rekursive methode vllt. doch nicht so effektiv?
und meine 2. frage is... enden rekursive funktionen die zu lang laufen (wie z.b. wenn ich damit alle 20 stelligen hashs berechne) nicht in nem stackoverflow? schließlich landet doch jeder wieder aufruf oben aufm stack und der erste aufruf bleibt ganz unten liegen. versteh ich da was falsch oder is das tatsächlich ein nachteil?In§@N¡T¥
-
13.06.2010, 23:24 #25print<>=~y/0-9//,$/
- Registriert seit
- 01.02.2010
- Beiträge
- 468
Rekursiv ist afaik sehr langsam.
+0x60Code:$_=<>;map$-+=$_,/./g;print$-,$/
-
13.06.2010, 23:28 #26Chloë Grace Moretz
- Registriert seit
- 29.05.2010
- Beiträge
- 384
Würde Sinn ergeben, vor Allem aufgrund der vielen calls, pushs und pops Zitat von 0x30
Zitat von 0x30



 Zitieren
Zitieren



Ähnliche Themen
-
Code Help! PLZ
Von unna456654 im Forum (X)HTML & CSSAntworten: 1Letzter Beitrag: 21.12.2008, 13:36
